https://programmers.co.kr/learn/courses/30/lessons/42893
코딩테스트 연습 - 매칭 점수
매칭 점수 프렌즈 대학교 조교였던 제이지는 허드렛일만 시키는 네오 학과장님의 마수에서 벗어나, 카카오에 입사하게 되었다. 평소에 관심있어하던 검색에 마침 결원이 발생하여, 검색개발팀
programmers.co.kr
🤷♂️ 풀이
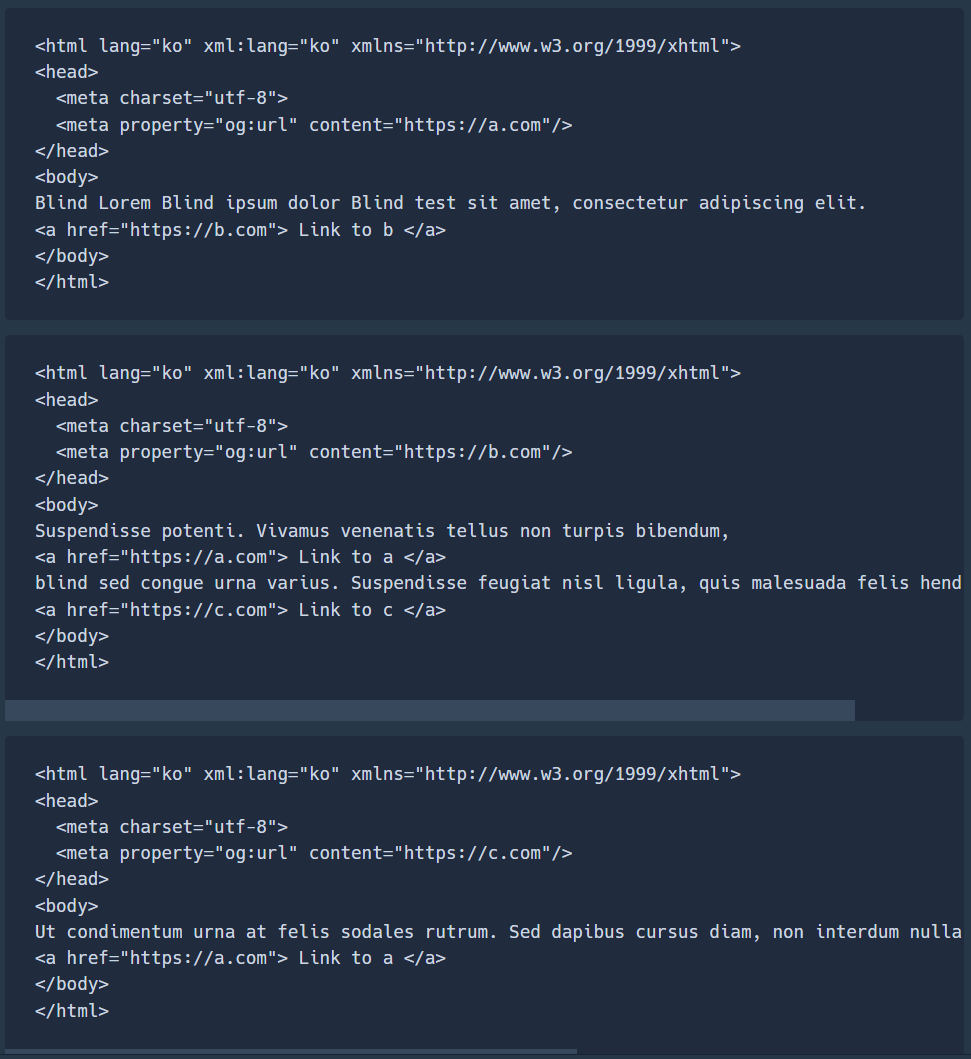
먼저 페이지의 제목을 따오는 작업이 필요하다
<meta property="og:url" content="https://a.com"/>
첫 번째 사이트인 a 사이트의 제목을 살펴보면 <meta property="og:url" content="(주소)" 인 구조로 돼있다
그럼 우리는 re.search를 이용해 해당 주소만 따오는 작업을 진행해야함을 알 수 있다
title = re.search('<meta property="og:url" content="(https://\S+)"', page).group(1)
여기서 우리는 주소를 불러오기위해 \S+를 사용해야하는데 . 을 사용하지않는 이유는
title = re.search('<meta property="og:url" content="(https://.+)"', page).group(1) 일 경우
<meta property="og:url" content="https://a.com"/> <"test"> 에서 뒤에 <"test 까지 다 불러오기 때문이다
\S 는 whitespace 문자가 아닌 것과 매치되는 문자 클래스이기 때문에 공백문자를 제외해서 주소만 불러오게 해준다
다음으로 기본점수를 알아내야한다
for find in re.findall('[a-zA-Z]+', page):
if find.upper() == word.upper():
basic_score[title] += 1- 예를들어 검색어가 "aba" 일 때, "abab abababa"는 단어 단위로 일치하는게 없으니, 기본 점수는 0점이 된다.
- 만약 검색어가 "aba" 라면, "aba@aba aba"는 단어 단위로 세개가 일치하므로, 기본 점수는 3점이다.
조건에서 다음과 같은 조건을 내걸고 있기 때문에 findall로 문자에 해당하는 모든 단어를 불러온다음 word와 비교한다
다음으로는 내가 가진 외부링크수와 나에게 오는 외부링크가 어디서오는지 알아야한다
외부링크 구조를 살펴보면 다음과 같다
<a href="https://a.com"> Link to a </a>
<a href="(외부링크)"의 구조이고 우리는 모든 외부링크를 알아내야 하기 때문에
for link in re.findall('<a href="(https://\S+)"', page):
exlink_cnt[title] += 1
if link in to_me_link:
to_me_link[link].append(title)
else:
to_me_link[link] = [title]
다음과 같이 써주어야한다
여기서도 뒤에 있는 "를 불러오는 오류를 없애주기 위해 \S를 써주었다
마지막으로 이제 종합점수를 구해주어야한다
for curr in basic_score:
link_score = 0
if curr in to_me_link:
for ex in to_me_link[curr]:
link_score += basic_score[ex] / exlink_cnt[ex]
total_score.append(basic_score[curr] + link_score)
basic_score의 dict에서 하나씩 불러온다
그 후 나에게 연결된 링크가 있는지 확인한다
if curr in to_me_link: 를 적어준 이유는 예제2 와 같이 나에게 연결된 링크가 없는경우가 존재하기 때문이다
외부링크의 (basic점수 / 외부링크수)로 링크점수를 알아내준후 더 해주면 최종 점수가 나오게 된다
이제 최종점수가 가장 높은 점수의 index를 출력해준다
😁 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import re
def solution(word, pages):
total_score = []
basic_score = {}
exlink_cnt = {}
to_me_link = {}
for page in pages:
title = re.search('<meta property="og:url" content="(https://\S+)"', page).group(1)
basic_score[title] = 0
exlink_cnt[title] = 0
for find in re.findall('[a-zA-Z]+', page):
if find.upper() == word.upper():
basic_score[title] += 1
for link in re.findall('<a href="(https://\S+)"', page):
exlink_cnt[title] += 1
if link in to_me_link:
to_me_link[link].append(title)
else:
to_me_link[link] = [title]
for curr in basic_score:
link_score = 0
if curr in to_me_link:
for ex in to_me_link[curr]:
link_score += basic_score[ex] / exlink_cnt[ex]
total_score.append(basic_score[curr] + link_score)
return total_score.index(max(total_score))
|
cs |

성공적으로 통과하는것을 확인할 수 있다